往期文章: 《00. Kotlin Jetpack 实战:开篇》 《09. 图解协程原理》 《10. 沉思录:开篇》
今天我们简单聊聊 Compose 的底层原理。 今年的Google I/O大会上,Android官方针对Jetpack Compose给出了一系列的性能优化建议,文档和视频都已经放出来了。总的来说,官方的内容都非常棒,看完以后我也有些意犹未尽。推荐你去看看。 不过,在聊「性能优化」之前,我们首先要懂「亿点点」Compose的底层原理。 一、Composable 的本质我们都知道,Jetpack Compose最神奇的地方就是:可以用 Kotlin 写UI界面(无需XML)。而且,借助Kotlin的高阶函数特性,Compose UI界面的写法也非常的直观。 // 代码段1@Composablefun Greeting() { // 1 Column { // 2 Text(text = "Hello") Text(text = "Jetpack Compose!") }}
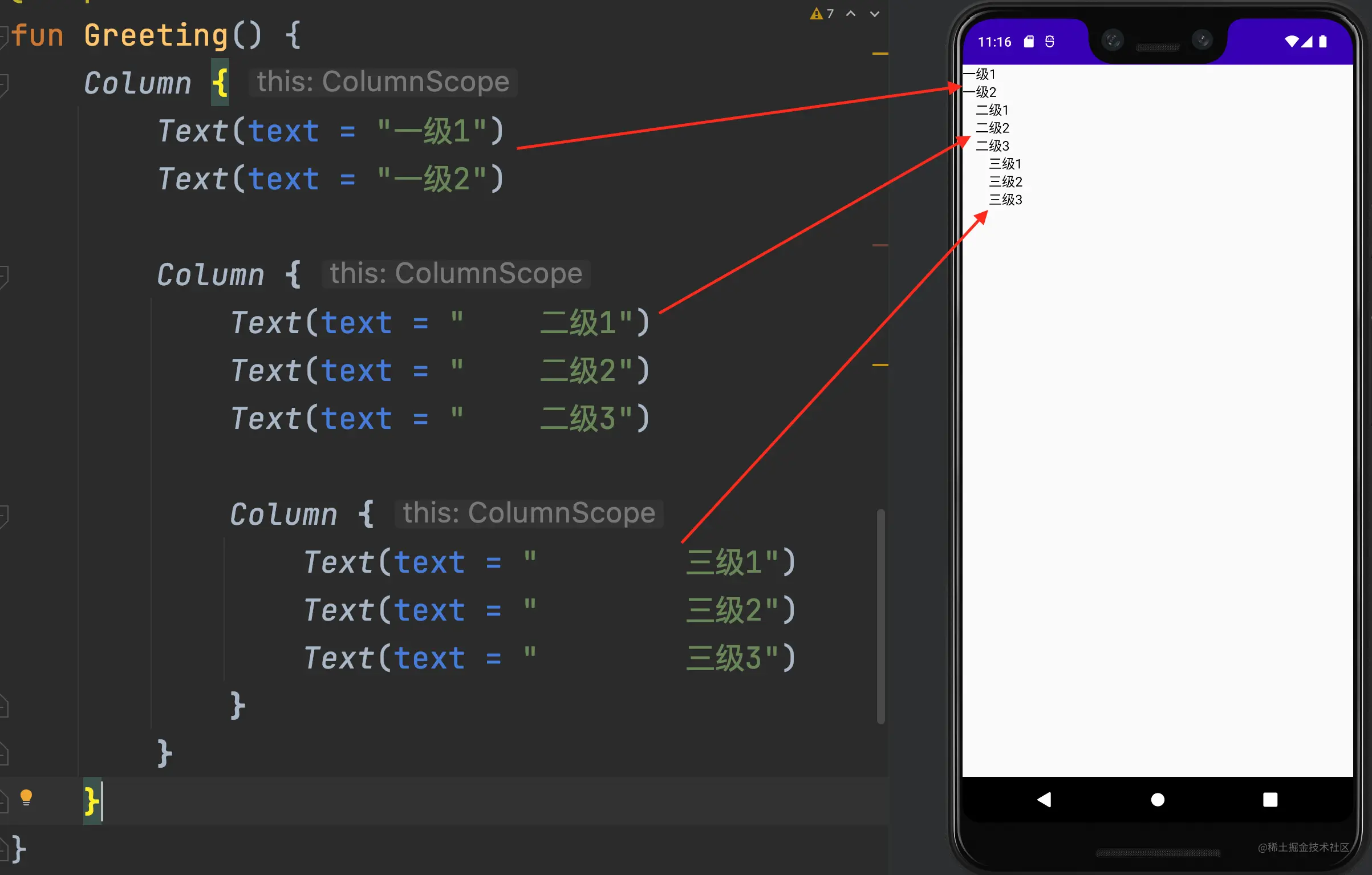
上面这段代码,即使你没有任何Compose基础,应该也可以轻松理解。Column相当于Android当中纵向的线性布局LinearLayout,在这个布局当中,我们放了两个Text控件。 最终的UI界面展示,如下图所示。 例子虽然简单,但是上面的代码中,还是有两个细节需要我们注意,我已经用注释标记出来了: 注释1,Greeting()它是一个Kotlin的函数,如果抛开它的@Composable注解不谈的话,那么,它的函数类型应该是() -> Unit。但是,由于@Composable是一个非常特殊的注解,Compose的编译器插件会把它当作影响函数类型的因子之一。所以,Greeting()它的函数类型应该是@Composable () -> Unit。(顺便提一句,另外两个常见的函数类型影响因子是:suspend、函数类型的接收者。) 注释2:Column {},请留意它的{},我们之所以可以这样写代码,这其实是Kotlin提供的高阶函数简写。它完整的写法应该是这样的: // 代码段2Column(content = { log(2) Text(text = "Hello") log(3) Text(text = "Jetpack Compose!")})
由此可见,Compose的语法,其实就是通过Kotlin的高阶函数实现的。Column()、Text()看起来像是在调用UI控件的构造函数,但它实际上只是一个普通的顶层函数,所以说,这只是一种DSL的“障眼法”而已。 备注:如果你想研究如何用Kotlin编写DSL,可以去看看我公众号的历史文章。
那么,到这里,我们其实可以做出一个阶段性的总结了:Composable的本质,是函数。这个结论看似简单,但它却可以为后面的原理研究打下基础。 接下来,我们来聊聊Composable的特质。 二、Composable 的特质前面我们已经说过了,Composable本质上就是函数。那么,它的特质,其实跟普通的函数也是非常接近的。这个话看起来像是废话,让我来举个例子吧。 基于前面的代码,我们增加一些log: // 代码段3@Composablefun Greeting() { log(1) Column { log(2) Text(text = "Hello") log(3) Text(text = "Jetpack Compose!") } log(4)}private fun log(any: Any) { Log.d("MainActivity", any.toString())}
请问,上面代码的输出结果是怎样的呢?如果你看过我的协程教程,那么心里肯定会有点“虚”,对吧?不过,上面这段代码的输出结果是非常符合直觉的。 // 输出结果// 注意:当前Compose版本为1.2.0-beta// 在未来的版本当中,Compose底层是可能做出优化,并且改变这种行为模式的。com.boycoder.testcompose D/MainActivity: 1com.boycoder.testcompose D/MainActivity: 2com.boycoder.testcompose D/MainActivity: 3com.boycoder.testcompose D/MainActivity: 4
你看,Composable不仅从源码的角度上看是个普通的函数,它在运行时的行为模式,跟普通的函数也是类似的。我们写出来的Composable函数,它们互相嵌套,最终会形成一个树状结构,准确来说是一个N叉树。而Composable函数的执行顺序,其实就是对一个N叉树的DFS遍历。 这样一来,我们写出来的Compose UI就几乎是:“所见即所得”。 也许,你会觉得,上面这个例子,也不算什么,毕竟,XML也可以做到类似的事情。那么,让我们来看另外一个例子吧。 // 代码段4@Composablefun Greeting() { log("start") Column { repeat(4) { log("repeat $it") Text(text = "Hello $it") } } log("end")}// 输出结果:com.boycoder.testcompose D/MainActivity: startcom.boycoder.testcompose D/MainActivity: repeat 0com.boycoder.testcompose D/MainActivity: repeat 1com.boycoder.testcompose D/MainActivity: repeat 2com.boycoder.testcompose D/MainActivity: repeat 3com.boycoder.testcompose D/MainActivity: end
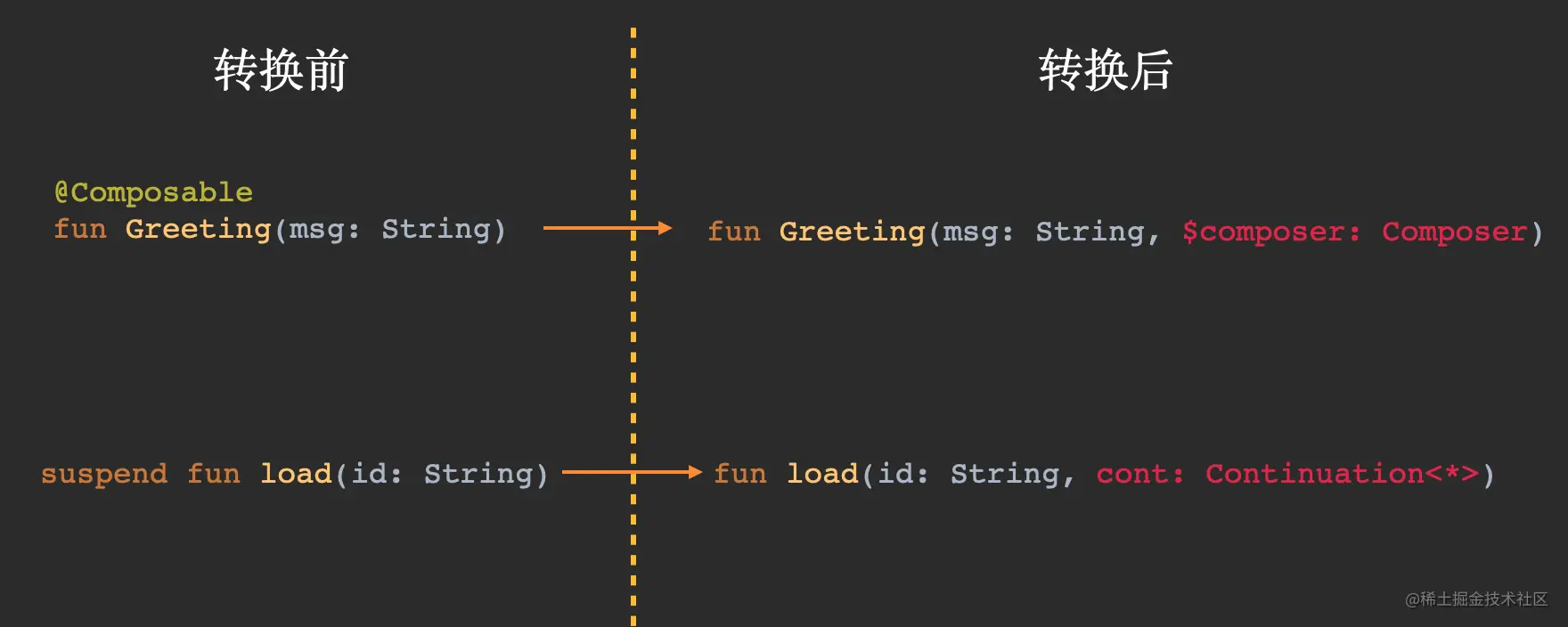
我们使用repeat{}重复调用了4次Text(),我们就成功在屏幕上创建了4个Text控件,最关键的是,它们还可以在Column{}当中正常纵向排列。这样的代码模式,在从前的XML时代是不可想象的。 话说回来,正是因为Composable的本质就是函数,它才会具备普通函数的一些特质,从而,也让我们可以像写普通代码一样,用逻辑语句来描述UI布局。 好了,现在我们已经知道了Composable的本质是函数,可是,我们手机屏幕上的那些UI控件是怎么出现的呢?接下来,我们需要再学「一点点」Compose编译器插件的知识。PS:这回,我保证真的是「一点点」。 三、Compose 编译器插件虽然Compose Compiler Plugin看起来像是一个非常高大上的东西,但从宏观概念上来看的话,它所做的事情还是很简单的。 如果你看过我的博客《图解协程原理》的话,你一定会知道,协程的suspend关键字,它可以改变函数的类型,Compose的注解@Composable也是类似的。总的来说,它们之间的对应关系是这样的: 具体来说,我们在Kotlin当中写的Composable函数、挂起函数,在经过编译器转换以后,都会被额外注入参数。对于挂起函数来说,它的参数列表会多出一个Continuation类型的参数;对于Composable函数,它的参数列表会多出一个Composer类型的参数。 为什么普通函数无法调用「挂起函数」和「Composable函数」,底层的原因就是:普通函数根本无法传入Continuation、Composer作为调用的参数。 注意:需要特殊说明的是,在许多场景下,Composable函数经过Compose Compiler Plugin转换后,其实还可能增加其他的参数。更加复杂的情况,我们留到后续的文章里再分析。
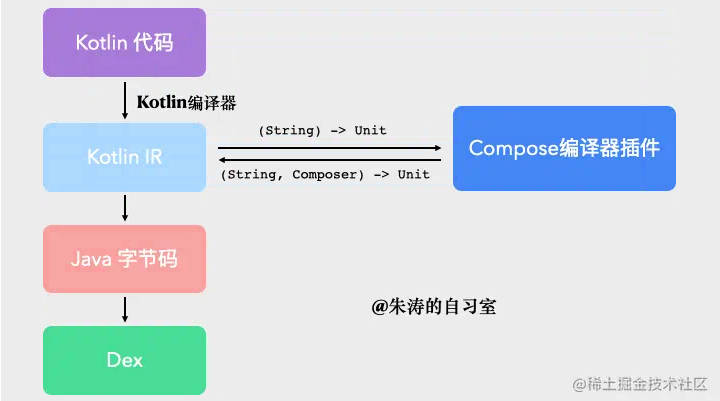
另外,由于Compose并不是属于Kotlin的范畴,为了实现Composable函数的转换,Compose团队是通过「Kotlin编译器插件」的形式来实现的。我们写出的Kotlin代码首先会被转换成IR,而Compose Compiler Plugin则是在这个阶段直接改变了它的结构,从而改变了最终输出的Java字节码以及Dex。这个过程,也就是我在文章开头放那张动图所描述的行为。 不过,Compose Compiler 不仅仅只是改变「函数签名」那么简单,如果你将Composable函数反编译成Java代码,你就会发现它的函数体也会发生改变。 让我们来看一个具体的例子,去发掘Compose的「重组」(Recompose)的实现原理。 四、Recompose 的原理// 代码段5class MainActivity : ComponentActivity() { // 省略 @Composable fun Greeting(msg: String) { Text(text = "Hello $msg!") }}
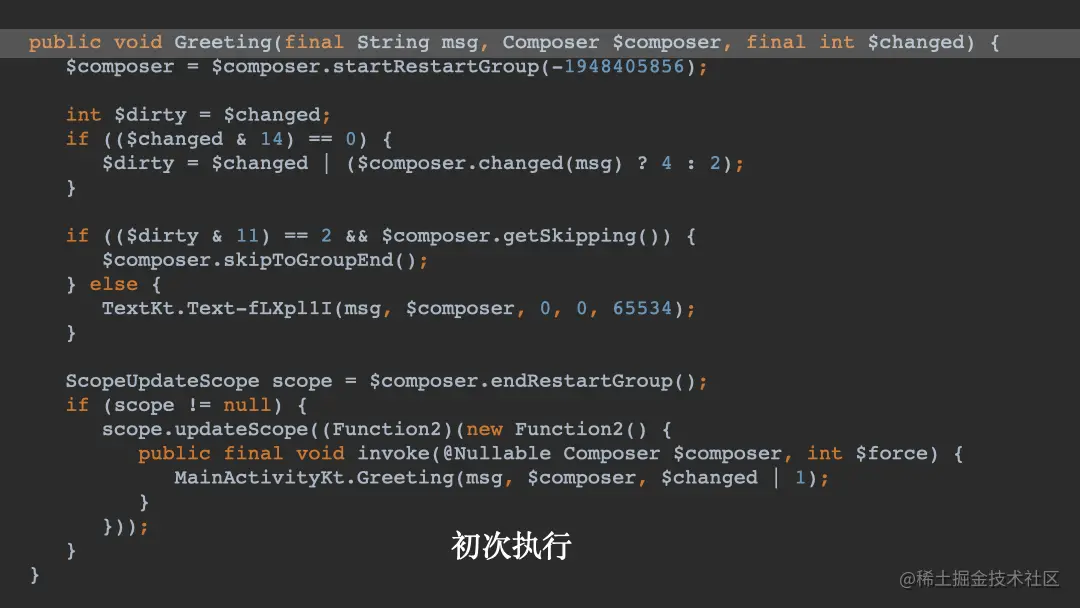
上面的代码很简单,Greeting()的逻辑十分简单,不过当它被反编译成Java后,它实际的逻辑会变复杂许多。 // 代码段6public static final void Greeting(final String msg, Composer $composer, final int $changed) { // 多出来的changed我们以后分析吧 // 1,开始 // ↓ $composer = $composer.startRestartGroup(-1948405856); int $dirty = $changed; if (($changed & 14) == 0) { $dirty = $changed | ($composer.changed(msg) ? 4 : 2); } if (($dirty & 11) == 2 && $composer.getSkipping()) { $composer.skipToGroupEnd(); } else { TextKt.Text-fLXpl1I(msg, $composer, 0, 0, 65534); } // 2,结束 // ↓ ScopeUpdateScope var10000 = $composer.endRestartGroup(); if (var10000 != null) { var10000.updateScope((Function2)(new Function2() { public final void invoke(@Nullable Composer $composer, int $force) { // 3,递归调用自己 // ↓ MainActivityKt.Greeting(msg, $composer, $changed | 1); } })); }}
毫无疑问,Greeting()反编译后,之所以会变得这么复杂,背后的原因全都是因为Compose Compiler Plugin。上面这段代码里值得深挖的细节太多了,为了不偏离主题,我们暂时只关注其中的3个注释,我们一个个看。 - 注释1,
composer.startRestartGroup,这是Compose编译器插件为Composable函数插入的一个辅助代码。它的作用是在内存当中创建一个可重复的Group,它往往代表了一个Composable函数开始执行了;同时,它还会创建一个对应的ScopeUpdateScope,而这个ScopeUpdateScope则会在注释2处用到。 - 注释2,
composer.endRestartGroup(),它往往代表了一个Composable函数执行的结束。而这个Group,从一定程度上,也描述了UI的结构与层级。另外,它也会返回一个ScopeUpdateScope,而它则是触发「Recompose」的关键。具体的逻辑我们看注释3。 - 注释3,我们往
ScopeUpdateScope.updateScope()注册了一个监听,当我们的Greeting()函数需要重组的时候,就会触发这个监听,从而递归调用自身。这时候你会发现,前面提到的RestartGroup也暗含了「重组」的意味。
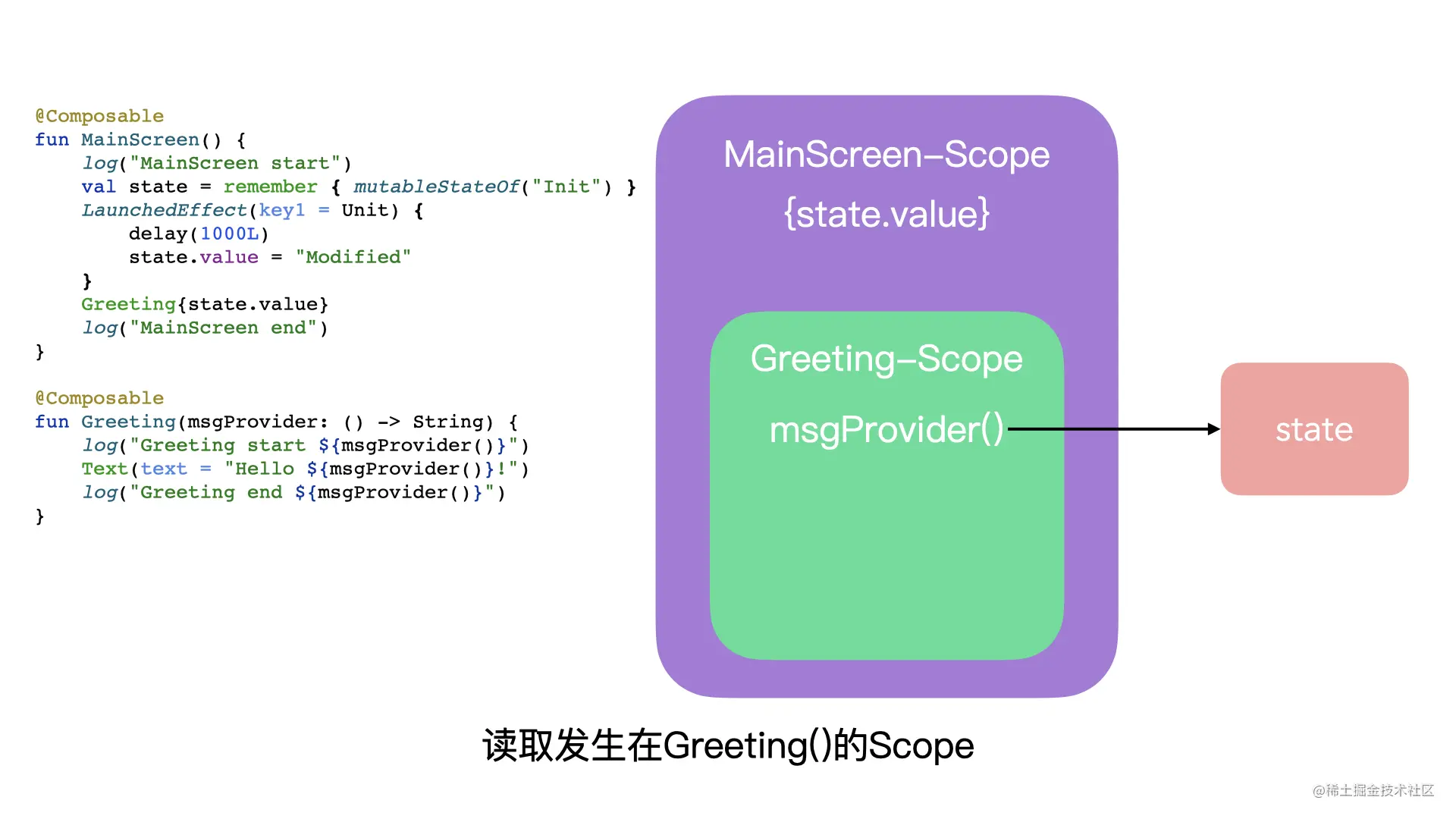
由此可见,Compose当中看起来特别高大上的「Recomposition」,其实就是:“重新调用一次函数”而已。 那么,Greeting()到底是在什么样的情况下才会触发「重组」呢?我们来看一个更加完整的例子。 // 代码段7class MainActivity : ComponentActivity() { override fun onCreate(savedInstanceState: Bundle?) { super.onCreate(savedInstanceState) setContent { MainScreen() } }}@Composablefun MainScreen() { log("MainScreen start") val state = remember { mutableStateOf("Init") } // 1 LaunchedEffect(key1 = Unit) { delay(1000L) state.value = "Modified" } Greeting(state.value) log("MainScreen end")}private fun log(any: Any) { Log.d("MainActivity", any.toString())}@Composablefun Greeting(msg: String) { log("Greeting start $msg") Text(text = "Hello $msg!") log("Greeting end $msg")}/* 输出结果 MainActivity: MainScreen startMainActivity: Greeting start InitMainActivity: Greeting end InitMainActivity: MainScreen end等待 1秒MainActivity: MainScreen start // 重组MainActivity: Greeting start Modified // 重组MainActivity: Greeting end Modified // 重组MainActivity: MainScreen end // 重组*/
上面的代码逻辑仍然十分的简单,setContent {}调用了MainScreen();MainScreen()调用了Greeting()。唯一需要注意的,就是注释1处的LaunchedEffect{},它的作用是启动一个协程,延迟1秒,并对state进行赋值。 从代码的日志输出,我们可以看到,前面4个日志输出,是Compose初次执行触发的;后面4个日志输出,则是由state改变导致的「重组」。看起来,Compose通过某种机制,捕捉到了state状态的变化,然后通知了MainScreen()进行了重组。 如果你足够细心的话,你会发现,state实际上只在Greeting()用到了,而state的改变,却导致MainScreen()、Greeting()都发生了「重组」,MainScreen()的「重组」看起来是多余。这里其实就藏着Compose性能优化的一个关键点。 注意:类似上面的情况,Compose Compiler 其实做了足够多的优化,MainScreen()的「重组」看似是多余的,但它实际上对性能的影响并不大,我们举这个例子只是为了讲明白「重组」的原理,引出优化的思路。Compose Compiler 具体的优化思路,我们留到以后再来分析。
让我们改动一下上面的代码: // 代码段8class MainActivity : ComponentActivity() { // 不变}@Composablefun MainScreen() { log("MainScreen start") val state = remember { mutableStateOf("Init") } LaunchedEffect(key1 = Unit) { delay(1000L) state.value = "Modified" } Greeting { state.value } // 1,变化在这里 log("MainScreen end")}private fun log(any: Any) { Log.d("MainActivity", any.toString())}@Composable // 2,变化在这里 ↓fun Greeting(msgProvider: () -> String) { log("Greeting start ${msgProvider()}") // 3,变化 Text(text = "Hello ${msgProvider()}!") // 3,变化 log("Greeting end ${msgProvider()}") // 3,变化}/*MainActivity: MainScreen startMainActivity: Greeting start InitMainActivity: Greeting end InitMainActivity: MainScreen end等待 1秒MainActivity: Greeting start Modified // 重组MainActivity: Greeting end Modified // 重组*/
代码的变化我用注释标记出来了,主要的变化在:注释2,我们把原先String类型的参数改为了函数类型:() -> String。注释1、3处改动,都是跟随注释2的。 请留意代码的日志输出,这次,「重组」的范围发生了变化,MainScreen()没有发生重组!这是为什么呢?这里涉及到两个知识点:一个是Kotlin函数式编程当中的「Laziness」;另一个是Compose重组的「作用域」。我们一个个来看。 4.1 LazinessLaziness 在函数式编程当中是个相当大的话题,要把这个概念将透的话,得写好几篇文章才行,这里我简单解释下,以后有机会我们再深入讨论。 理解 Laziness 最直观的办法,就是写一段这样对比的代码: // 代码段9fun main() { val value = 1 + 2 val lambda: () -> Int = { 1 + 2 } println(value) println(lambda) println(lambda())}
其实,如果你对Kotlin高阶函数、Lambda理解透彻的话,你马上就能理解代码段8当中的Laziness是什么意思了。如果你对这Kotlin的这些基本概念还不熟悉,可以去看看我公众号的历史文章。 上面这段代码的输出结果如下: 3Function03
这样的输出结果也很好理解。1 + 2是一个表达式,当我们把它用{}包裹起来以后,它就一定程度上实现了Laziness,我们访问lambda的时候并不会触发实际的计算行为。只有调用lambda()的时候,才会触发实际的计算行为。 Laziness讲清楚了,我们来看看Compose的重组「作用域」。 4.2 重组「作用域」其实,在前面的代码段6处,我们就已经接触过它了,也就是ScopeUpdateScope。通过前面的分析,我们每个Composable函数,其实都会对应一个ScopeUpdateScope,Compiler底层就是通过注入监听,来实现「重组」的。 实际上,Compose底层还提供一个:状态快照系统(SnapShot)。Compose的快照系统底层的原理还是比较复杂的,以后有机会我们再深入探讨,更多信息你可以看看这个链接。 总的来说,SnapShot 可以监听Compose当中State的读、写行为。 // 代码段10@Stableinterface MutableState : State { override var value: T}internal open class SnapshotMutableStateImpl( value: T, override val policy: SnapshotMutationPolicy) : StateObject, SnapshotMutableState { override var value: T get() = next.readable(this).value set(value) = next.withCurrent { if (!policy.equivalent(it.value, value)) { next.overwritable(this, it) { this.value = value } } }}
本质上,它其实就是通过自定义Getter、Setter来实现的。当我们定义的state变量,它的值从“Init”变为“Modified”的时候,Compose可以通过自定义的Setter捕获到这一行为,从而调用ScopeUpdateScope当中的监听,触发「重组」。 那么,代码段7、代码段8,它们之间的差异到底在哪里呢?关键其实就在于ScopeUpdateScope的不同。 这其中的关联,其实用一句话就可以总结:状态读取发生在哪个Scope,状态更新的时候,哪个Scope就发生重组。 如果你看不懂这句话也没关系,我画了一个图,描述了代码段7、代码段8之间的差异: 对于代码段7,当state的读取发生在MainScreen()的ScopeUpdateScope,那么,当state发生改变的时候,就会触发MainScreen()的Scope进行「重组」。 代码段8也是同理: 现在,回过头来看这句话,相信你就能看懂了:状态读取发生在哪个Scope,状态更新的时候,哪个Scope就发生重组。 好,做完前面这些铺垫以后,我们就可以轻松看懂Android官方给出的其中三条性能优化建议了。 - Defer reads as long as possible.
- Use derivedStateOf to limit recompositions
- Avoid backwards writes
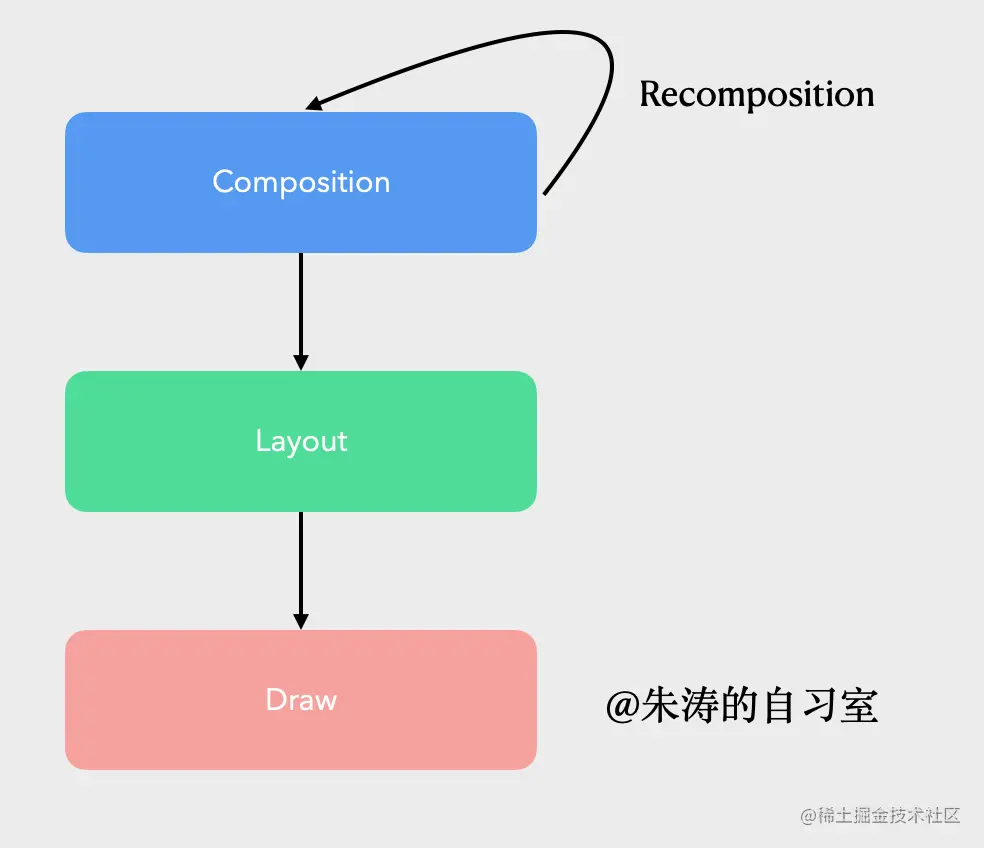
以上这3条建议,本质上都是为了尽可能避免「重组」,或者缩小「重组范围」。由于篇幅限制,我们就挑第一条来详细解释吧~ 五、尽可能延迟State的读行为其实,对于我们代码段7、代码段8这样的改变,Compose的性能提升不明显,因为Compiler底层做了足够多的优化,多一个层级的函数调用,并不会有明显差异。Android官方更加建议我们将某些状态的读写延迟到Layout、Draw阶段。 这就跟Compose整个执行、渲染流程相关了。总的来说,对于一个Compose页面来说,它会经历以下4个步骤: - 第一步,Composition,这其实就代表了我们的Composable函数执行的过程。
- 第二步,Layout,这跟我们View体系的Layout类似,但总体的分发流程是存在一些差异的。
- 第三步,Draw,也就是绘制,Compose的UI元素最终会绘制在Android的Canvas上。由此可见,Jetpack Compose虽然是全新的UI框架,但它的底层并没有脱离Android的范畴。
- 第四步,Recomposition,重组,并且重复1、2、3步骤。
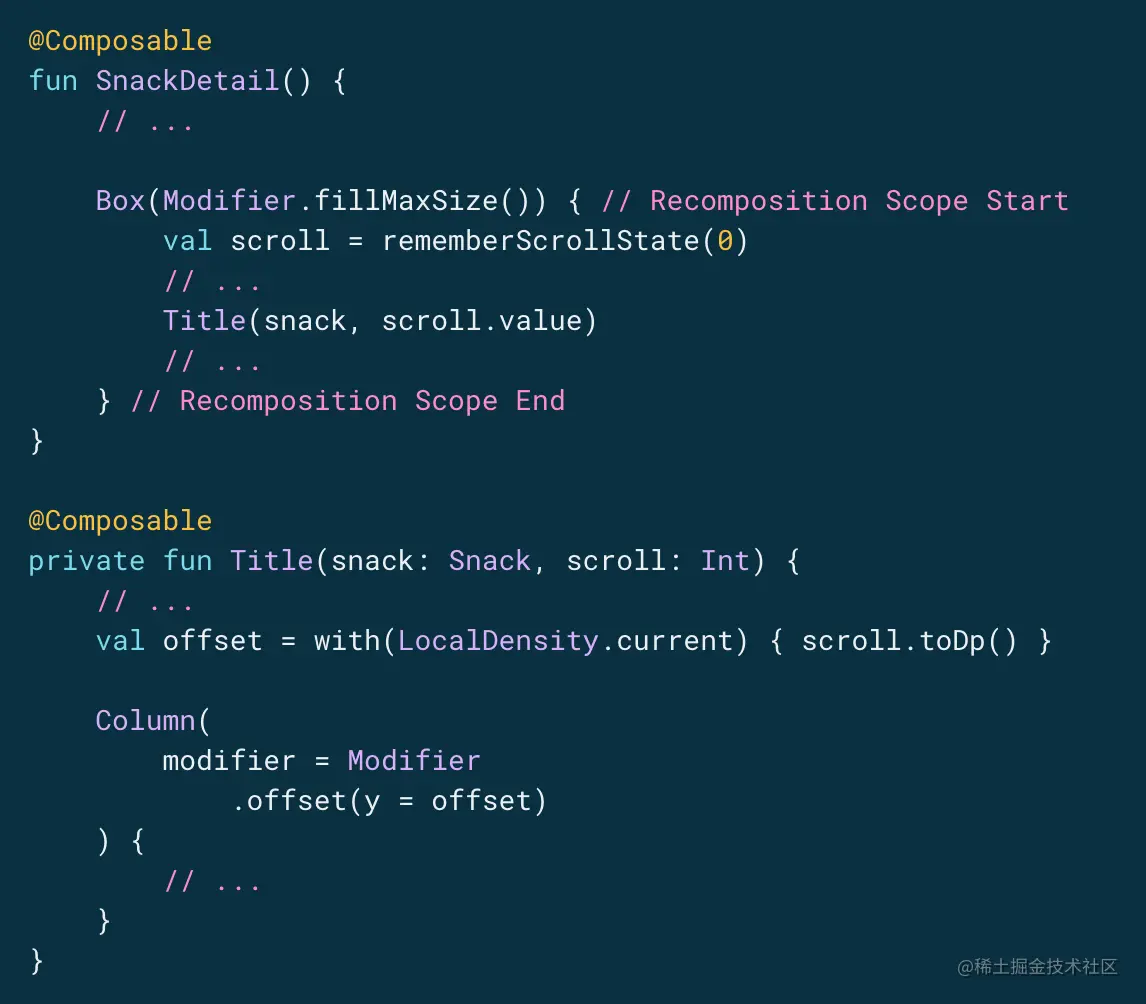
总体的过程如下图所示: Android官方推荐我们尽可能推迟状态读取的原因,其实还是希望我们可以在某些场景下直接跳过Recomposition的阶段、甚至Layout的阶段,只影响到Draw。 而实现这一目标的手段,其实就是我们前面提到的「Laziness」思想。让我们以官方提供的代码为例: 首先,我要说明的是,Android官方文档当中的注释其实是存在一个小瑕疵的。它对新手友好,但容易对我们深入底层的人产生困扰。上面代码中描述的Recomposition Scope并不准确,它真正的Recomposition Scope,应该是整个SnackDetail(),而不是Box()。对此,我已经在Twitter与相关的Google工程师反馈了,对方也回复了我,这是“故意为之”的,因为这更容易理解。具体细节,你可以去这条Twitter看看。 好,我们回归正题,具体分析一下这个案例: // 代码段11@Composablefun SnackDetail() { // Recomposition Scope // ... Box(Modifier.fillMaxSize()) { Start val scroll = rememberScrollState(0) // ... Title(snack, scroll.value) // 1,状态读取 // ... } // Recomposition Scope End}@Composableprivate fun Title(snack: Snack, scroll: Int) { // ... val offset = with(LocalDensity.current) { scroll.toDp() } Column( modifier = Modifier .offset(y = offset) // 2,状态使用 ) { // ... }}
上面的代码有两个注释,注释1,代表了状态的读取;注释2,代表了状态的使用。这种“状态读取与使用位置不一致”的现象,其实就为Compose提供了性能优化的空间。 那么,具体我们该如何优化呢?其实很简单,借助我们之前Laziness的思想,让:“状态读取与使用位置一致”。 // 代码段12@Composablefun SnackDetail() { // Recomposition Scope // ... Box(Modifier.fillMaxSize()) { Start val scroll = rememberScrollState(0) // ... Title(snack) { scroll.value } // 1,Laziness // ... } // Recomposition Scope End}@Composableprivate fun Title(snack: Snack, scrollProvider: () -> Int) { // ... val offset = with(LocalDensity.current) { scrollProvider().toDp() } Column( modifier = Modifier .offset(y = offset) // 2,状态读取+使用 ) { // ... }}
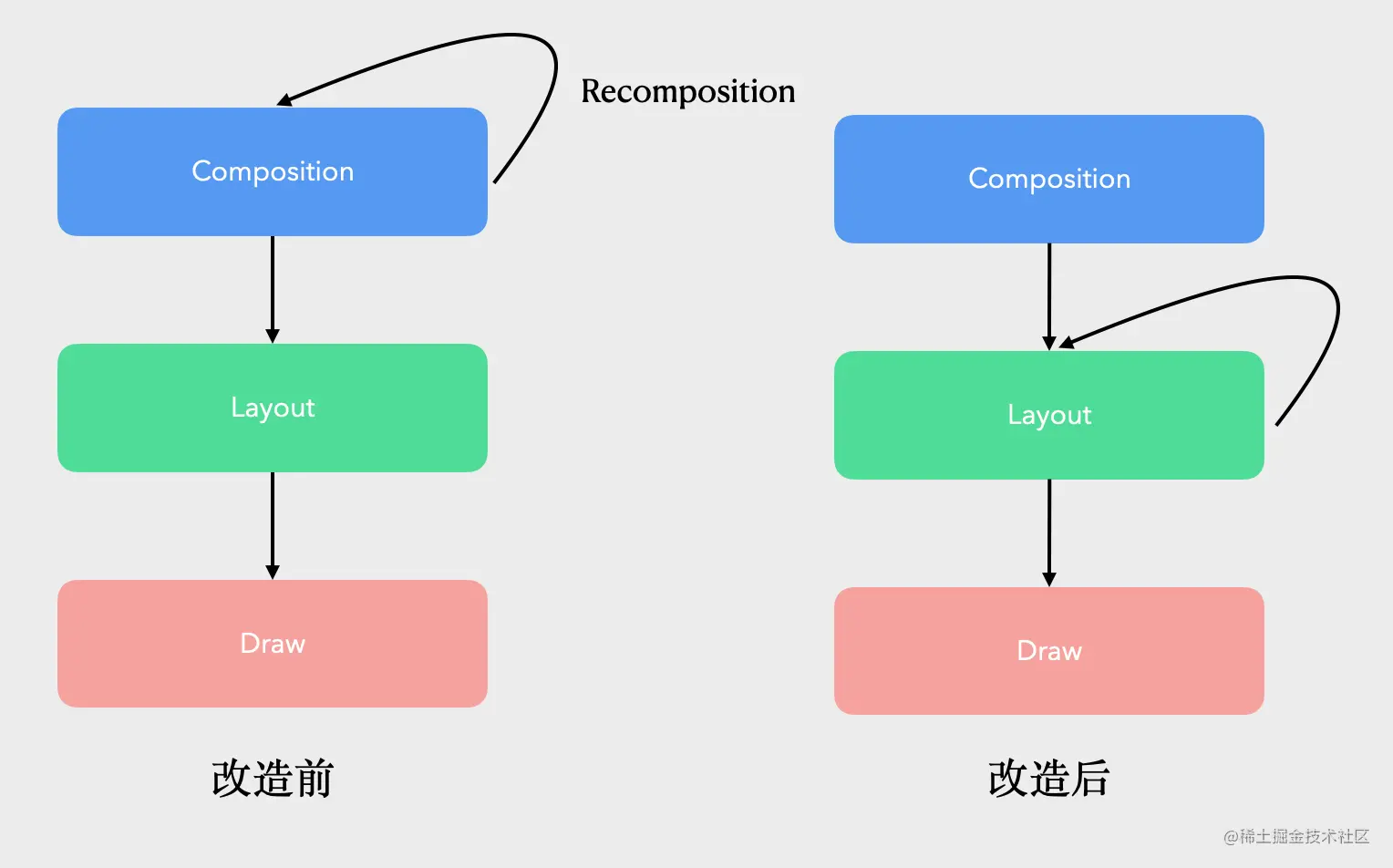
请留意注释1这里的变化,由于我们将scroll.value变成了Lambda,所以,它并不会在composition期间产生状态读取行为,这样,当scroll.value发生变化的时候,就不会触发「重组」,这就是「Laziness」的意义。 代码段11、代码段12之间的差异是巨大的: 前者会在页面滑动的期间频繁触发:「重组」+「Layout」+「Draw」,后者则完全绕过了「重组」,只有「Layout」+「Draw」,由此可见,它的性能提升也是非常显著的。 六、结尾OK,到这里,我们这篇文章就该结束了。我们来简单总结一下: - 第一,Composable函数的本质,其实就是函数。多个Composable函数互相嵌套以后,就自然形成了一个UI树。Composable函数执行的过程,其实就是一个DFS遍历过程。
- 第二,
@Composable修饰的函数,最终会被Compose编译器插件修改,不仅它的函数签名会发生变化,它函数体的逻辑也会有天翻地覆的改变。函数签名的变化,导致普通函数无法直接调用Composable函数;函数体的变化,是为了更好的描述Compose的UI结构,以及实现「重组」。 - 第三,重组,本质上就是当Compose状态改变的时候,Runtime对Composable函数的重复调用。这涉及到Compose的快照系统,还有ScopeUpdateScope。
- 第四,由于ScopeUpdateScope取决于我们对State的读取位置,因此,这就决定了我们可以使用Kotlin函数式编程当中的Laziness思想,对Compose进行「性能优化」。也就是让:状态读取与使用位置一致,尽可能缩小「重组作用域」,尽可能避免「重组」发生。
- 第五,今年的Google I/O大会上,Android官方团队提出了:5条性能优化的最佳实践,其中3条建议的本质,都是在践行:状态读取与使用位置一致的原则。
- 第六,我们详细分析了其中的一条建议「尽可能延迟State的读行为」。由于Compose的执行流程分为:「Composition」、「Layout」、「Draw」,通过Laziness,我们可以让Compose跳过「重组」的阶段,大大提升Compose的性能。
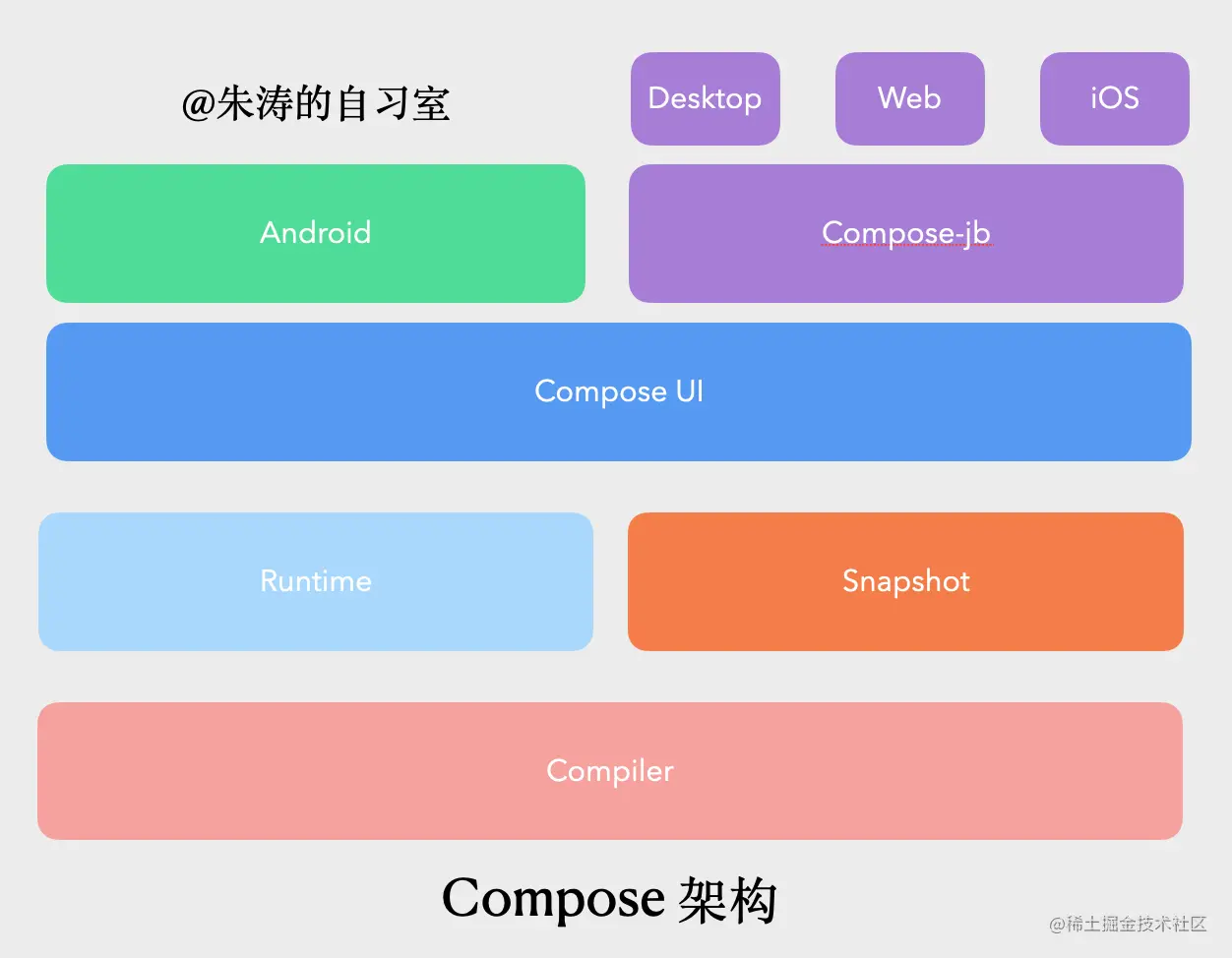
七、结束语其实,Compose的原理还是相当复杂的。它除了UI层跟Android有较强的关联以外,其他的部分Compiler、Runtime、Snapshot都是可以独立于Android以外而存在的。这也是为什么JetBrains可以基于Jetpack Compose构建出Compose-jb的原因。 这篇文章是「沉思录」系列的第二篇文章,后续除了Compose以后,还会有《Kotlin Jetpack 实战》系列,敬请期待。 作者:朱涛的自习室
链接:https://juejin.cn/post/7103336251645755429
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作! |